









[캠퍼스人+스토리]고려대·아이젠사이언스·I.C.L 공동 연구팀 개발… 74점으로 높은 점수 받아
|

|

11일 고려대에 따르면 연구팀의 Meerkat-7B은 미국 의사 면허 시험에서 74점을 받았다. 60점이 평균 합격선인 미국 의사 면허 시험에서 높은 점수를 획득하면서 그 성능을 입증했다.
Meerkat-7B은 매개변수가 70억개 이하인 소형 언어 모델이다. 소형 언어 모델은 매개변수가 기존 거대 언어 모델 보다 적고, 훈련하는 데 드는 데이터나 시간, 비용이 상대적으로 작다. 또 다른 애플리케이션과 통합하기 쉽다는 장점이 있다.
OpenAI, 구글 등 빅테크 회사들이 주도하는 거대 언어 모델들이 현재 큰 성과를 보이고 있다. 그러나 이는 외부 클라우드를 사용하기 때문에 병원이나 기업 등에서 사용하기에는 민감한 데이터 유출될 위험이 있다는 우려가 있다. 이에 보안성을 높일 수 있는 소형 언어 모델에 대한 수요가 증가하는 추세다.
|
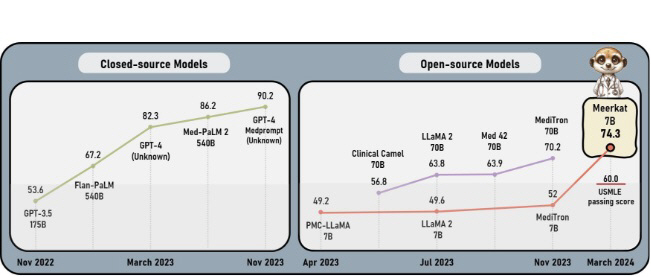
이 외에도 Meerkat-7B는 7개의 의료 벤치마크 성능평가에서 GPT-3.5(175B) 모델보다 평균 13% 높은 성능을 보였다.
강 교수는 Meerkat-7B가 복잡한 의료 문제를 해결하는 데 필요한 다단계 추론 능력을 갖춘 의생명 분야에 특화된 소형 언어 모델이라고 보고 있다. 특히 의생명 특화 언어모델은 병원 내 임상 의사 결정을 지원해 준다. 비표준화된 의료 차트를 정리 해주면서 의료·원무 행정의 효율성을 높여주기도 한다.
강 교수는 "제약 회사에서는 특허 분석, 임상 설계, 문서 작성 등의 노동 집약적이고 전문성을 요하는 업무를 지원해 각 분야 전문가의 업무 부담을 경감하는 데 기여할 수 있다"며 "Meerkat-7B를 통해 새로운 약물 타겟을 발굴하는 과정의 효율성을 대폭 향상시킬 수 있을 것으로 기대한다"고 말했다.
한편 강 교수는 이번 성과를 바탕으로 의료 특화 거대 언어 모델을 활용한 신규 사업을 준비할 예정이다.






